|
Hanyang Wang | 汪晗阳 I'm currently a first-year master's student in the Department of Electronic Engineering at Tsinghua University , advised by Prof. Yueqi Duan. In 2025, I obtained my B.Eng. in the Department of Computer Science and Technology at Tsinghua University. I'm also working closely with Fangfu Liu. My research interests lie in 3D Computer Vision, Video Generation, and AIGC. |

|
Research
* indicates equal contribution. Some papers are highlighted. |
|
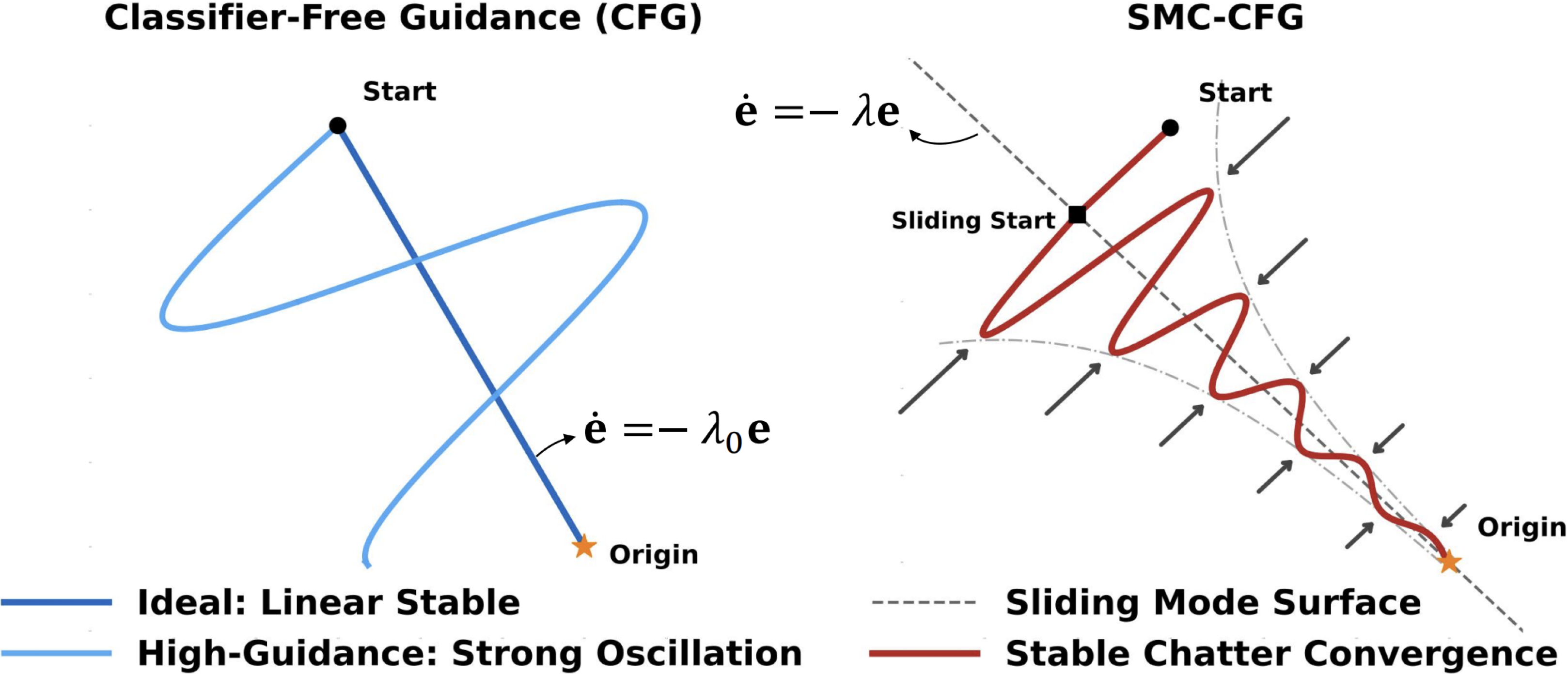
Hanyang Wang* , Yiyang Liu*, Jiawei Chi, Fangfu Liu , Ran Xue , Yueqi Duan IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2026 [arXiv] [Code] [Project Page] We propose CFG-Ctrl, a unified framework that reinterprets CFG as a control applied to the first-order continuous-time generative flow. Based on this control-theoretic view, we further introduce SMC-CFG, which uses sliding mode control to drive the flow toward a rapidly convergent sliding manifold. |
|
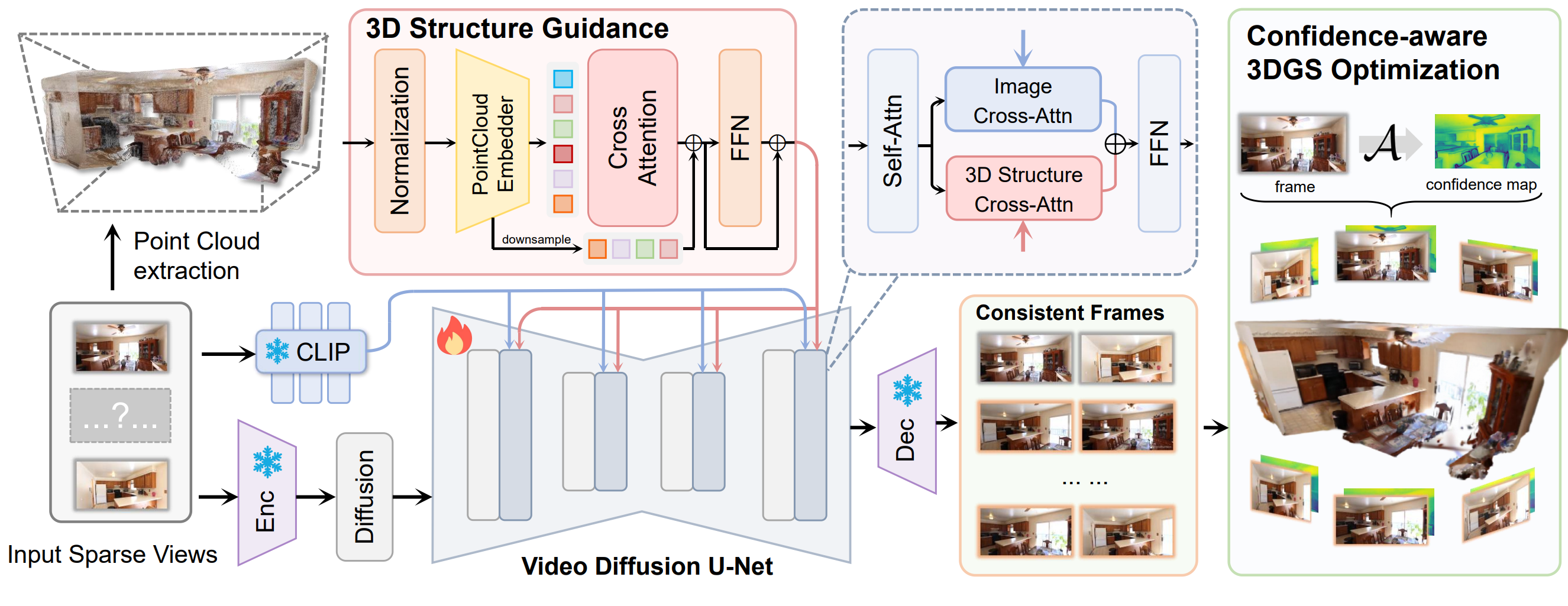
Fangfu Liu*, Wenqiang Sun* , Hanyang Wang* , Yikai Wang , Haowen Sun , Junliang Ye , Jun Zhang , Yueqi Duan IEEE Transactions on Image Processing (TIP), 2025 [arXiv] [Code] [Project Page] In this paper, we propose ReconX, a novel 3D scene reconstruction paradigm that reframes the ambiguous reconstruction challenge as a temporal generation task. The key insight is to unleash the strong generative prior of large pre-trained video diffusion models for sparse-view reconstruction. |
|
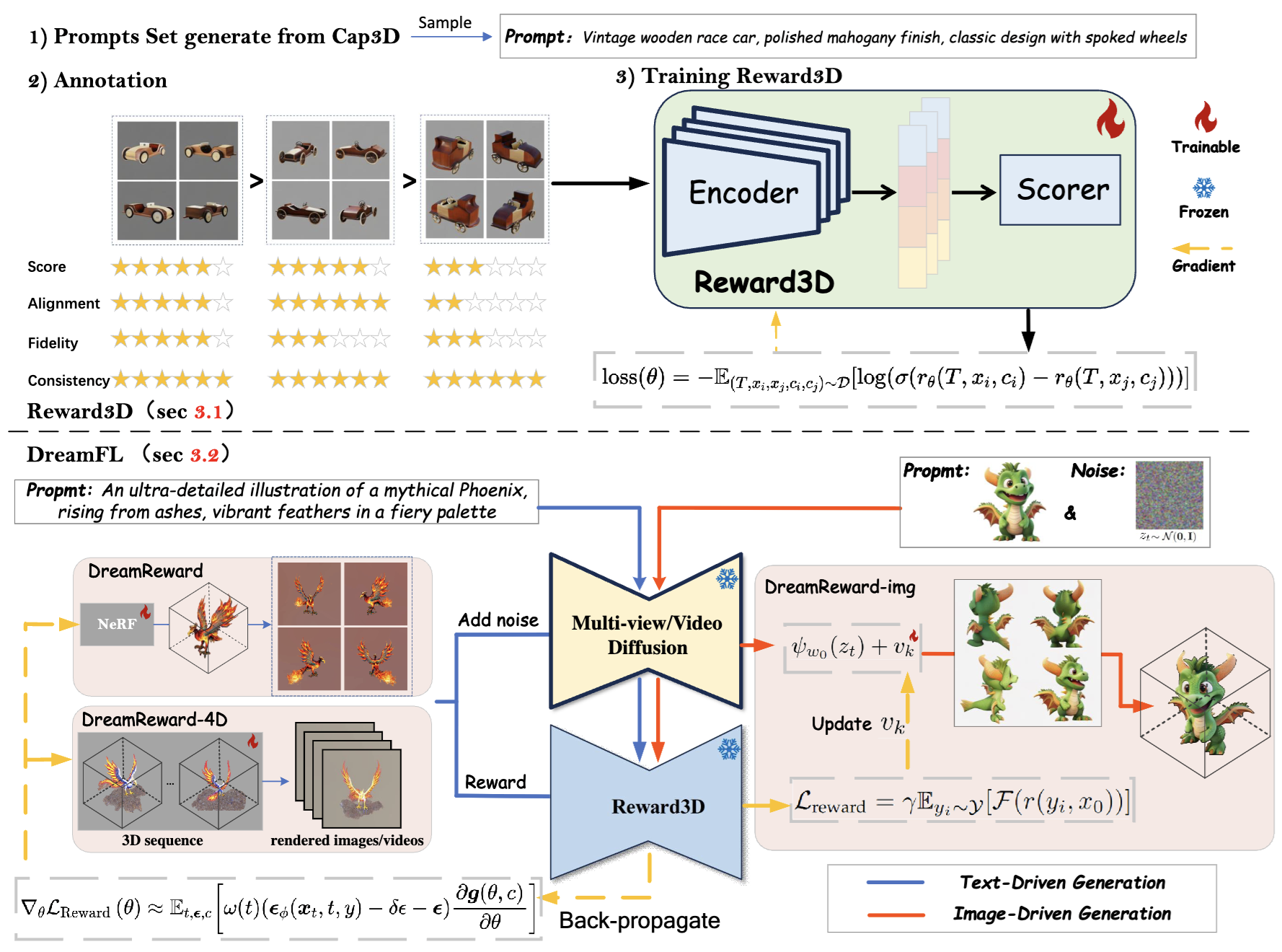
Fangfu Liu , Junliang Ye , Yikai Wang , Hanyang Wang , Zhengyi Wang , Jun Zhu , Yueqi Duan IEEE Transactions on Pattern Analysis and Machine Intelligence (TPAMI), 2025 [arXiv] [Code] [Project Page] We present a comprehensive framework, coined DreamReward-X, where we introduce a reward-aware noise sampling strategy to unleash text-driven diversity during the generation process while ensuring human preference alignment. Our results demonstrate the great potential for learning from human feedback to improve 3D generation. |

|
Fangfu Liu, Hao Li , Jiawei Chi , Hanyang Wang , Minghui Yang, Fudong Wang, Yueqi Duan IEEE International Conference on Computer Vision (ICCV), 2025 [arXiv] [Code] [Project Page] In this paper, we introduce a novel generative framework, coined LangScene-X, to unify and generate 3D consistent multi-modality information for reconstruction and understanding. |

|
Fangfu Liu*, Hanyang Wang* , Yimo Cai, Kaiyan Zhang , Xiaohang Zhan , Yueqi Duan IEEE International Conference on Computer Vision (ICCV), 2025 [arXiv] [Code] [Project Page] We present the generative effects and performance improvements of video generation under test-time scaling (TTS) settings. The videos generated with TTS are of higher quality and more consistent with the prompt than those generated without TTS. |

|
Hanyang Wang*, Fangfu Liu*, Jiawei Chi , Yueqi Duan IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2025 (Highlight) [arXiv] [Code] [Project Page] In this paper, we propose VideoScene to distill the video diffusion model to generate 3D scenes in one step, aiming to build an efficient and effective tool to bridge the gap from video to 3D. |
|
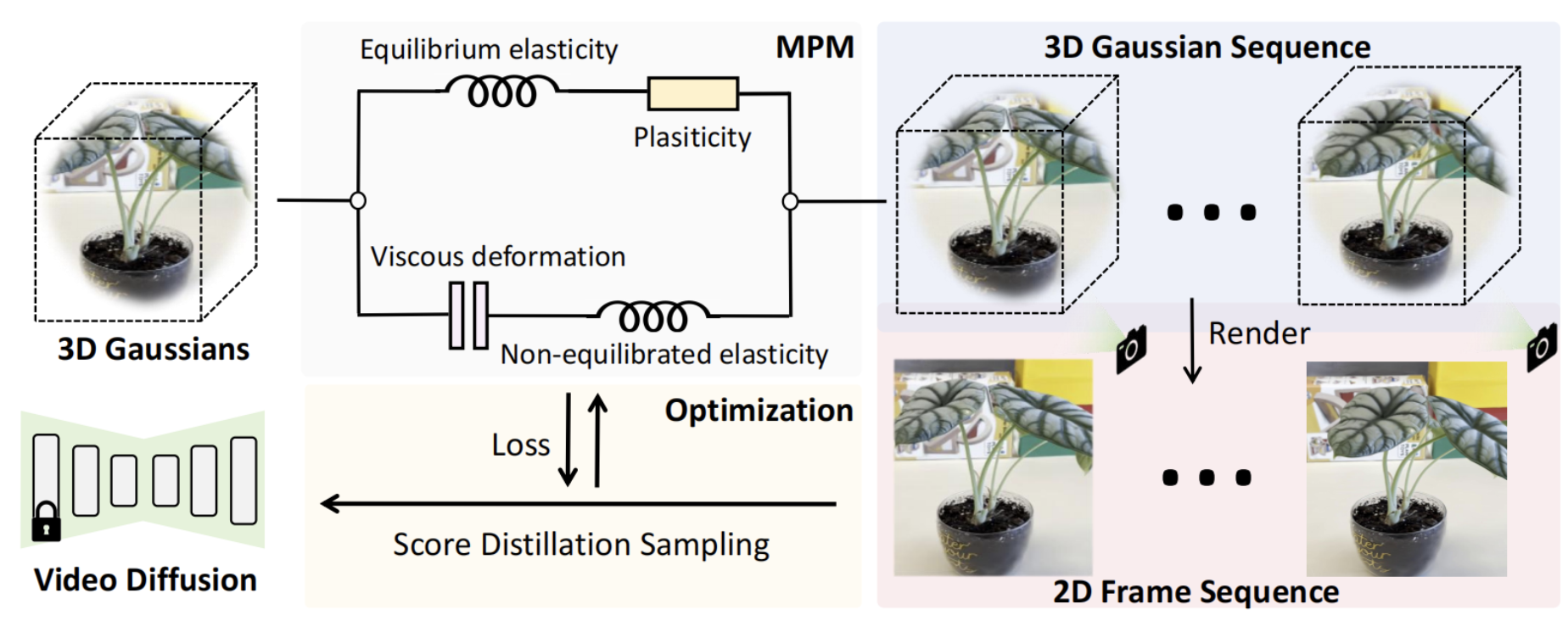
Fangfu Liu*, Hanyang Wang* Shunyu Yao , Shengjun Zhang, Jie Zhou, Yueqi Duan Arxiv, 2024 [arXiv] [Code] [Project Page] In this paper, we propose Physics3D, a novel method for learning various physical properties of 3D objects through a video diffusion model. Our approach involves designing a highly generalizable physical simulation system based on a viscoelastic material model, which enables us to simulate a wide range of materials with high-fidelity capabilities. |

|
Kailu Wu , Fangfu Liu, Zhihan Cai, Runjie Yan, Hanyang Wang, Yating Hu, Yueqi Duan , Kaisheng Ma Conference on Neural Information Processing Systems (NeurIPS), 2024 [arXiv] [Code] [Project Page] In this work, we introduce Unique3D, a novel image-to-3D framework for efficiently generating high-quality 3D meshes from single-view images, featuring state-of-the-art generation fidelity and strong generalizability. Unique3D can generate a high-fidelity textured mesh from a single orthogonal RGB image of any object in under 30 seconds. |

|
Fangfu Liu, Hanyang Wang, Weiliang Chen, Haowen Sun, Yueqi Duan European Conference on Computer Vision (ECCV), 2024 [arXiv] [Code] [Project Page] We introduce a novel 3D customization method, dubbed Make-Your-3D that can personalize high-fidelity and consistent 3D content from only a single image of a subject with text description within 5 minutes. |
|
|